Have you ever wondered how so many systems in our lives automatically sort and organize data for us? For example, by simply entering a customer’s data into the system, airlines can generate lists of customers in economy class and business class to prioritize onboarding. Perhaps you work in the sales department. The company’s system allows you to sort sales data based on a number of criteria, including the number of sales, salesperson, or products sold.
All this is done thanks to high-level programming and one of the most important foundations of language programming – data structures. Each language may present some structural nuances. In today’s article, we’ll learn about the magic of data structures in Java, why it matters, and learn the variety and magic of its different types of data structures.
Key Takeaways:
- Data structures refer to the way data is organized.
- The main types of data structures in Java include array, linked list, stack, queue, binary tree, binary search tree, heap, hashing, and graph.
- Each data structure holds its own unique features, functions, and use cases.
- Even though every data structure’s main aim is to store and find data, the various features serve different purposes for the fastest and most convenient data management.
Understanding Data Structure
A data structure, in the simplest sense, is the way we organize data in the computer memory to produce desired results.
In more detail, a data structure organizes and stores data in computer memory so it can be accessed, modified, and managed efficiently. Think of it as a container that holds information in a specific format, enabling faster and more effective data processing. From simple lists to complex trees and graphs, data structures are the backbone of how programs handle information, making them essential for performance and scalability in any software system.
In Java, data structures play a key role in managing and organizing information within applications. The language offers a variety of built-in structures; each is designed for different types of operations and use cases. The main kinds of data structures in Java are:
- Array
- Linked list
- Stack
- Queue
- Binary tree
- Binary search tree
- Heap
- Hashing
- Graph
Why Use Data Structures in Java
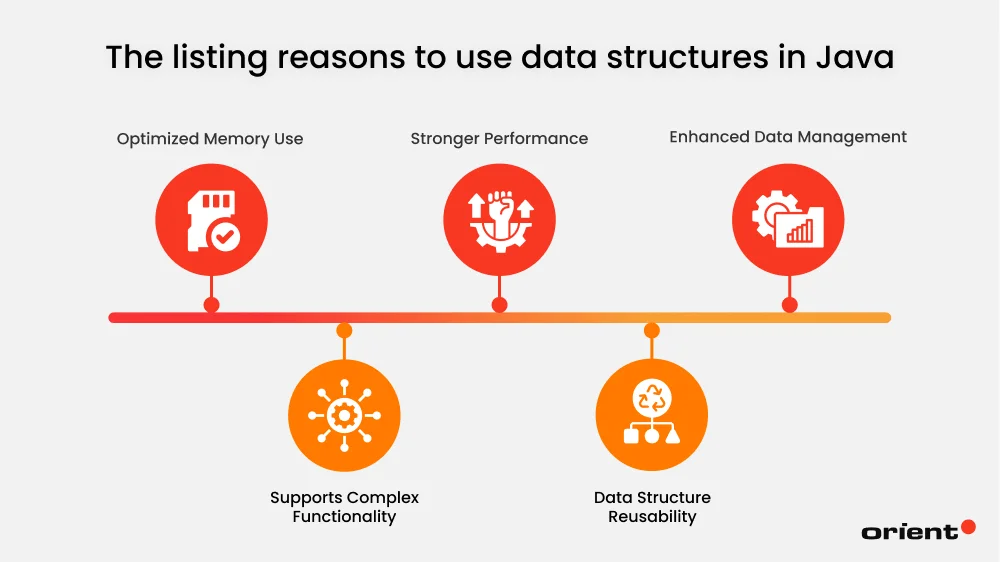
The importance of data structures in Java goes beyond effective data processing and usage.
Optimized Memory Use
Data structures impact memory usage. Different structures result in different application efficiency due to the differences in data allocation and deallocation. Proper structures that fit the specific goals reduce memory wastage and boost efficient memory use.
Supports Complex Functionality
Java data structure allows the efficient execution of complicated tasks that would have been impossible to achieve with basic data types. They allow developers to build relationships between data nodes and even build an entire intricate network.
Stronger Performance
Smart data structures allow the application to reduce processing time. This is especially important as the app’s data volume will inevitably increase. Shorter data time cycle means faster performance, fewer bottlenecks, and enhanced user experience.
Data Structure Reusability
Once a data structure is put in place, it can be reused across the program, even in other projects, as long as it fits the specific purpose. This not only saves time but also increases the modularity of an app.
Enhanced Data Management
Gathering data in one place makes it easier and faster to organize, access, and complete tasks. The right data structures make every task – whether you are searching or modifying data – much faster. It also makes spotting errors easier, increases readability, and leads to an overall productivity boost.
Better Problem-Solving
Every data structure in Java, from the most basic to the complex ones, aims to solve common problems in Java. These structures help developers understand the nature of the problem and program, and have high-level and ready-to-use tools to solve potential problems efficiently.
It’s time we dig in deep and learn what each Java data structure entails.
Arrays and Their Implementation
An array is a fundamental data structure in almost every aspect of Java programming. An array refers to a data structure that stores a collection of the same data types.
Let’s take a look at an array example of students’ scores.
int[] scores = {85, 90, 78, 92, 88};
Let’s break that down:
int means each item is an integer (a whole number).[ ] shows that this is an array.- The curly braces
{ } contain the actual data, which in this case is five scores.
The main features of arrays are:
- Memory in arrays is created dynamically, which means the computer decides how much memory it is using during running or execution time, saving storage.
- The elements are stored under a single name and stored side by side for quick retrieval.
Arrays in Java are used for:
- Storing similar data types
- Quick and easy access for easy searching, inserting, sorting, deleting, etc.
- Serve as building blocks for more complex data structures
- Used for mathematical tasks.
Pros and Cons of Arrays
The main advantages of arrays are as follows:
- With the help of indexes, developers can access elements randomly.
- It allows easy storing, sorting, and manipulation of data.
However, the limits of arrays can be:
- Arrays can only store similar types of data.
- The size of the data is fixed, meaning it can’t be increased or decreased once declared.
- The memory needs to be contiguous (next to one another) to be allocated.
Types of Arrays
Depending on the specific aim of a task, you can utilize different types of arrays.
One-dimensional Array
A one-dimensional array holds a list of elements in a single row. It is also known as a linear array. The data will be stored in boxes like this:
Here is an array example of city names
String[] cities = {"Hanoi", "Tokyo", "Paris", "New York"};
Two-dimensional Array
Two-dimensional arrays are stored in rows and columns. Imagine it’s something like this:
Below is a specific example of a table with two rows and three columns:
int[][] numbers = {
{1, 2, 3},
{4, 5, 6}
};
System.out.println(numbers[0][0]); // Prints 1 (first row, first column)
System.out.println(numbers[1][2]); // Prints 6 (second row, third column)
Multi-dimensional Array
A combination of two or more arrays, or in other words, it is an array of arrays. Here is a quick example:
public class MultiDimensionalArrayExample {
public static void main(String[] args) {
int[][][] numbers = {
{ {1, 2, 3}, {4, 5, 6} },
{ {7, 8, 9}, {10, 11, 12} }
};
System.out.println(numbers[0][0][1]); // Prints 2
System.out.println(numbers[1][1][2]); // Prints 12
}
}
The output would look something like this:
2
12
Linked List Concepts
A linked list data structure is a linear data structure, similar to arrays. However, there are important differences:
- The elements aren’t stored contiguously (not next to one another).
- Linked lists are a flexible way to organize information, linking data in a sequence.
- A node in a linked list consists of data and a reference or a link to the next (or previous) node in the sequence. This allows easy insertions and deletions.
- The first node in the list is called the head. It is a reference to the entire list. It is a null reference if the link is empty.
A linked list’s main features to keep in mind include:
- Java’s linked list is a dynamic data structure, which means its size is not fixed. You can add and remove elements from the list.
- The elements are stored in containers, and each one has a link to the next node in the list.
- Adding a new element to the list means you add a new container that is linked to other containers (nodes).
There are three main types of linked lists:
- Singular linked list
- Doubly linked list
- Circular linked list
How to Create a Linked List
In Java, creating a linked list requires you to master the following tasks:
- Creating a node
- Linking the nodes
- Append the nodes
- Insert the nodes
- Deleting a node
Let’s take a closer look at how to achieve these tasks with simple examples.
Creating a Node
A node holds two things — data (like a number or word) and a link to the next node.
class Node {
int data;
Node next;
Node(int data) { this.data = data; }
}
Connect Nodes:
You link one node to the next using the next pointer.
Node first = new Node(10);
Node second = new Node(20);
first.next = second; // Connect first to second
Append Nodes (add at the end):
Go to the last node and link a new one after it.
Node third = new Node(30);
second.next = third; // Add to the end
Insert Nodes (add in the middle):
Create a new node and adjust the links so it fits between two existing nodes.
Node newNode = new Node(15);
newNode.next = second;
first.next = newNode; // Insert between first and second
Delete nodes:
Skip over the node you want to remove by changing the link.
first.next = second.next; // Removes 'second' node
Stack Data Structure in Java
A stack is a linear data structure. Even though it is simple in nature, it is powerful and has multiple applications. Imagine a stack of plates, where you can only add or remove new ones at the top. If you wish to remove the plate at the very bottom, you’ll need to remove all the ones on top first. This analogy represents how a stack in Java works.
A stack is a great data structure for tracking the current events or reversing the most recent ones. Other applications of a stack include:
- Recursion: They store temporary data during recursive calls, helping the program remember its current state.
- Memory management: Some systems use stacks to manage and organize memory efficiently.
- Function calls: Stacks keep track of where a program should return after a function finishes running.
- Expression evaluation: Stacks make it easier to solve expressions written in postfix (Reverse Polish) notation.
- Syntax parsing: They help check if code or expressions are written correctly.
- Problem-solving: Stacks are the foundation for classic problems like Next Greater Element, Largest Area in a Histogram, and the Stock Span Problem.
Key Features and Operations of a Stack
The most crucial feature of a stack is that it follows the LIFO, or last-in, first-out principle. What this means is that the latest element inserted is also the first one to be removed. Developers can only access a stack from the top, and the insertion or removal of an element is also done from the very top.
This leads us to the stack’s core operations:
- Push: inserting an element at the top
- Pop: removing an element
- IsEmpty: checking if the stack is empty
- IsFull: checking if the stack is full
- Peek: getting to the top element of the stack but not removing it
Stacks are simple and efficient, managing data using the LIFO principle. However, it is not suitable for random access and has the potential to overflow, causing data loss.
Implementing Stack in Java Programming
One common approach to implementing a stack is using a linked list (using arrays is also another common stack implementation method).
public class LinkedStack {
private Node top; // the top (head) node of the stack
private class Node {
int data;
Node next;
Node(int data) {
this.data = data;
this.next = null;
}
}
public LinkedStack() {
top = null; // initially, stack is empty
}
public boolean isEmpty() {
return top == null;
}
public void push(int x) {
Node newNode = new Node(x);
newNode.next = top; // link new node to current top
top = newNode; // new node becomes the new top
}
public int pop() {
if (isEmpty()) {
System.out.println("Stack is empty");
return -1; // or throw exception
}
int value = top.data;
top = top.next; // remove top node
return value;
}
public int peek() {
if (isEmpty()) {
System.out.println("Stack is empty");
return -1;
}
return top.data;
}
public void display() {
Node curr = top;
System.out.print("Stack: ");
while (curr != null) {
System.out.print(curr.data + " ");
curr = curr.next;
}
System.out.println();
}
public static void main(String[] args) {
LinkedStack stack = new LinkedStack();
stack.push(10);
stack.push(20);
stack.push(30);
stack.display(); // prints: Stack: 30 20 10
System.out.println(stack.pop()); // prints: 30
stack.display(); // prints: Stack: 20 10
System.out.println(stack.peek()); // prints: 20
}
}
Queue Data Structure in Java
A queue is another linear data structure, but it follows the first-in-first-out (FIFO) rule. Unlike stack data structures, the items are removed in the order they are inserted. Think of a line at a bank, or any service line in our daily lives. The first one to arrive is served first and leaves first.
Queue Key Features and Operations
A queue is made up of two main parts: the front and the back. Insertion can take place from the front, and deletion takes place from the back. Here is a visual example for easy visualization:
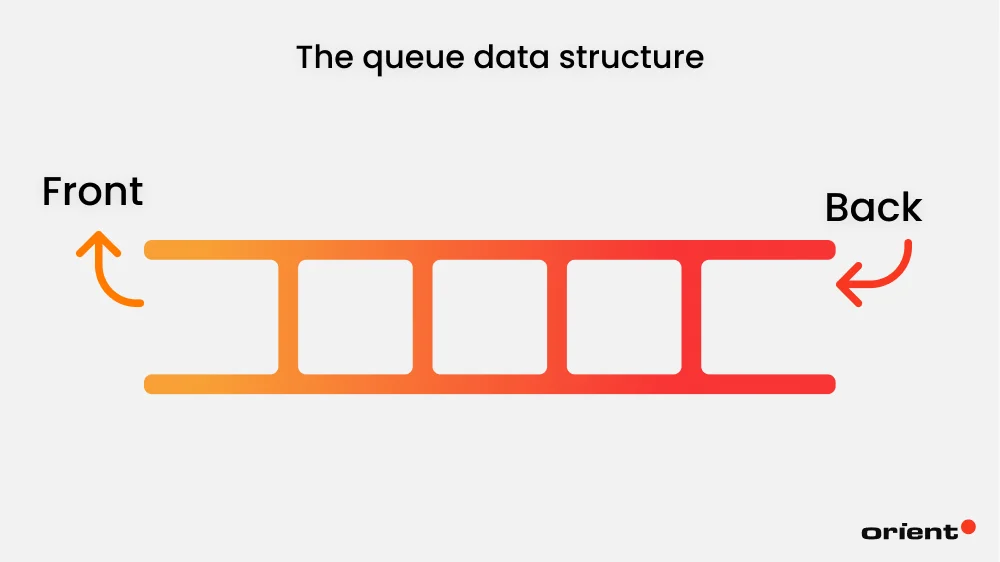
The structure of your queue doesn’t have to be fixed – you can have the front on the right and the back on the left.
To remove and insert items to your queue, here are the key operations that you need to know:
- Enqueue: adding an element to the back end of the queue
- Dequeue: removing an element
- Front/Peek: to get the first element of the queue without removing it.
- IsEmpty: checking if the queue is empty
- IsFull: checking if the queue is full.
Queue Implementation in Java
Similar to a stack, there are several approaches to queue implementation (e.g., using an array or a priority queue). Here is a simple example using linked lists that automatically resizes and applies the FIFO principle seamlessly.
import java.util.*;
public class QueueExample {
public static void main(String[] args) {
Queue< Integer > q = new LinkedList<>();
q.add(10);
q.add(20);
q.add(30);
System.out.println(q); // Output: [10, 20, 30]
q.remove(); // Removes 10
System.out.println(q.peek()); // Shows 20 (front element)
System.out.println(q); // Output: [20, 30]
}
}
Priority Queue
A special type of queue data structure is a priority queue. Instead of following the FIFO rule, a priority queue removes an element based on a priority level. You can think about boarding priorities in flights: business class passengers are prioritized and board first, then come the other passengers in economy class.
There are several ways to implement a priority queue. You can use a linked list, an array, a binary search tree, or a heap data structure. A heap data structure is considered to be the most effective implementation.
Binary Trees
Binary trees are a hierarchical data structure that produces the magic behind hierarchical data processing and data storage.
It is made up of nodes, and each node can have at most two children. The parent node contains the reference to the child notes, often called the right child node and the left child node.
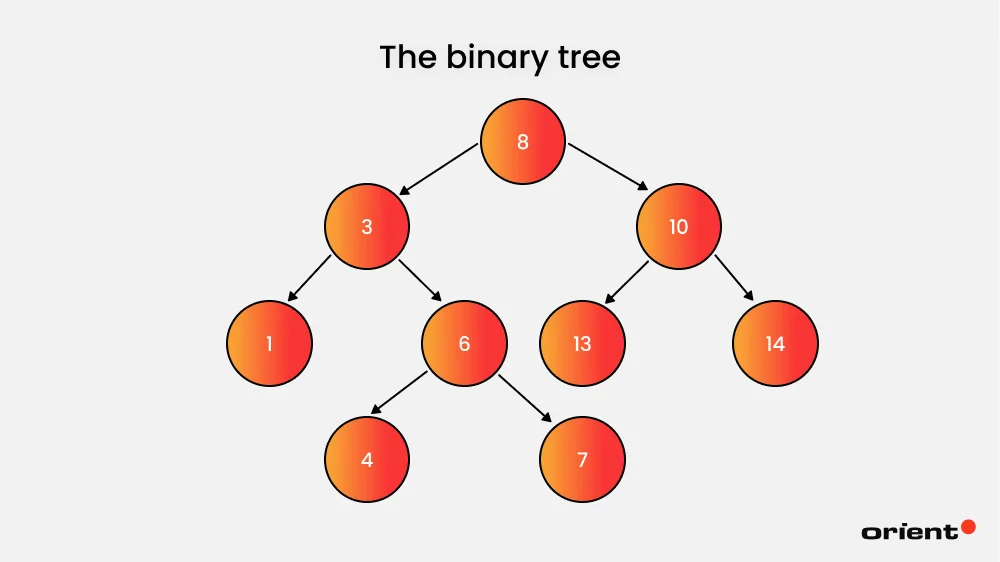
Thanks to its clarity and simplicity, binary trees are often utilized in file systems, computer science algorithms, and more. Common binary operations include insertion of new elements, deletion of elements, and finding an element.
Binary Tree Types
There are seven common types of binary trees.
- Full Binary Tree. Every node has 0 or 2 children.
- Complete Binary Tree. All levels are filled except possibly the last, which is filled from left to right.
- Perfect Binary Tree. Both are complete; all leaves are on the same level.
- Balanced Binary Tree. The height difference between the left and right subtrees is at most 1.
- Binary Search Tree (BST). Left child < parent < right child; used for fast searching and sorting.
- Degenerate (Skewed) Binary Tree. Each node has only one child; it behaves like a linked list.
- Threaded Binary Tree. Uses links instead of null pointers to enable faster in-order traversal.
Code Example of Binary Tree Data Structure
Here is an example of a binary tree with five nodes that will print the nodes in order.
class Node {
int value;
Node left, right;
// Constructor to create a new node
Node(int item) {
value = item;
left = right = null;
}
}
class BinaryTree {
// Root node of the tree
Node root;
// Constructor
BinaryTree() {
root = null;
}
// Display tree in-order (Left → Root → Right)
void inOrder(Node node) {
if (node == null)
return;
inOrder(node.left);
System.out.print(node.value + " ");
inOrder(node.right);
}
public static void main(String[] args) {
BinaryTree tree = new BinaryTree();
// Create tree nodes
tree.root = new Node(1);
tree.root.left = new Node(2);
tree.root.right = new Node(3);
tree.root.left.left = new Node(4);
tree.root.left.right = new Node(5);
System.out.println("In-order traversal of the binary tree:");
tree.inOrder(tree.root);
}
}
Binary Search Trees
A Binary Search Tree (BST) is a special kind of binary tree where every node follows a simple rule: values on the left are smaller than the parent, and values on the right are larger.
This structure keeps data neatly organized, making it faster to search, insert, and delete information. Think of it like an efficient filing system that automatically sorts new entries as they’re added. By maintaining this order, BSTs help developers perform operations quickly and solve complex problems more effectively.
A binary search tree’s advantage is that it maintains the nodes in order, making finding the min and max nodes in the tree easy. However, it does add complexity and doesn’t leave space for random access.
Heaps Data Structures
Heap data structures are complete binary trees that satisfy the heap property. Every item, or node, is arranged in a specific order. The root node is compared with the children and then arranged in a specific order. This relationship between the parent and child node is called the heap property.
There are two types of heaps:
- Max heap: The parent node is larger than or equal to its children.
- Min heap: The parent node is smaller than or equal to its children
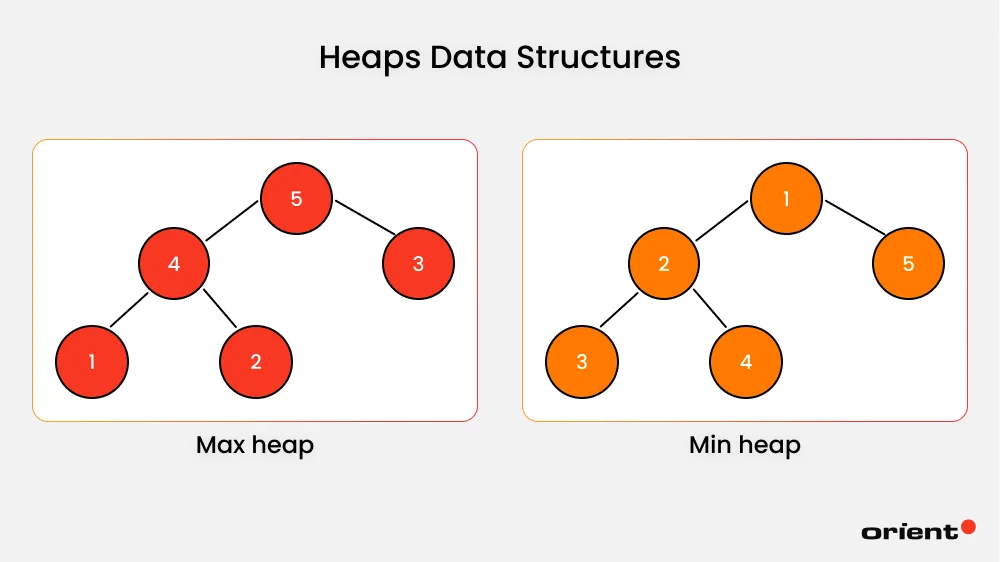
Heap Data Structure Operations
Like most data structures, heaps allow basic operations such as inserting, deleting, and viewing elements. Let’s look at the main ones briefly.
- Heapify: This process turns an unsorted array into a max-heap, where every parent is larger than its children. It works from the bottom up, swapping elements until the heap property is satisfied.
- Insertion: When you add a new element, it’s first placed at the bottom. Then it “bubbles up”, or in other words, it swaps with its parent until it reaches the correct spot and the heap property is restored.
- Deletion: To remove an element, swap it with the last one, delete it, and then heapify again to fix the order.
- Peek: This simply looks at the top value, the largest in a max-heap or the smallest in a min-heap, without removing it.
Implementation of Heap Data Structure
Below is an example of a max heap data structure using his uses Java’s built-in PriorityQueue with Collections.reverseOrder().
import java.util.PriorityQueue;
import java.util.Collections;
public class MaxHeapExample {
public static void main(String[] args) {
// Create a max heap using PriorityQueue
PriorityQueue< Integer > maxHeap =
new PriorityQueue<>(Collections.reverseOrder());
// Add elements
maxHeap.add(10);
maxHeap.add(20);
maxHeap.add(15);
maxHeap.add(30);
maxHeap.add(40);
maxHeap.add(5);
System.out.println("Max Heap: " + maxHeap);
// Remove the largest element
System.out.println("Extracted Max: " + maxHeap.poll());
System.out.println("After extraction: " + maxHeap);
}
}
Utilizing Hash-Based Structures
In Java, hashing is a technique to store and retrieve data. This technique is used to convert data of any size into a fixed-size value, known as a hash code. Think of it as giving every piece of data its own unique ID based on its content.
This process is done using a hash function, which applies a mathematical formula to generate the hash. A few notes on hash functions include:
- You can’t restore or retrieve the original data from its hash, as it is a one-directional process.
- A specific hash function always produces the same, fixed output.
- To minimize the risk of collision (when multiple keys generate the same index), the hash function should reach a certain level of complexity. Collisions are often handled by utilizing chaining or open addressing.
As a result, developers can quickly locate where the data is stored, where it should be retrieved from a structure often referred to as a hash table. It is a simple and easy way to locate addresses inside a vast data system.
Two forms of hashing often used in Java are HashSet and HashMap.
- HashMap stores data in key-value pairs, allowing quick lookups, insertions, and deletions using keys.
- HashSet is built on top of HashMap, but only keeps unique elements, meaning no duplicates are allowed.
- Hashtable is an older, synchronized version of HashMap. It’s thread-safe but generally less efficient and less flexible than modern alternatives.
Hash-based data structures are a great way to store elements and fetch them constantly, but potential collisions do add a layer of complication to this data structure.
Example of HashMap Code
Below is an example of a HashMap of fruit names and their quantities that allows the addition, removal, and retrieval of items.
import java.util.HashMap;
public class SimpleHashMapExample {
public static void main(String[] args) {
// Create a HashMap
HashMap< String, Integer > map = new HashMap<>();
// Add key-value pairs
map.put("Apple", 3);
map.put("Banana", 5);
map.put("Orange", 2);
// Access a value using its key
System.out.println("Bananas: " + map.get("Banana"));
// Remove a key-value pair
map.remove("Orange");
// Print all key-value pairs
System.out.println("Current map: " + map);
}
}
Graph Java Data Structure
A graph is a non-linear data structure made up of vertices and edges.
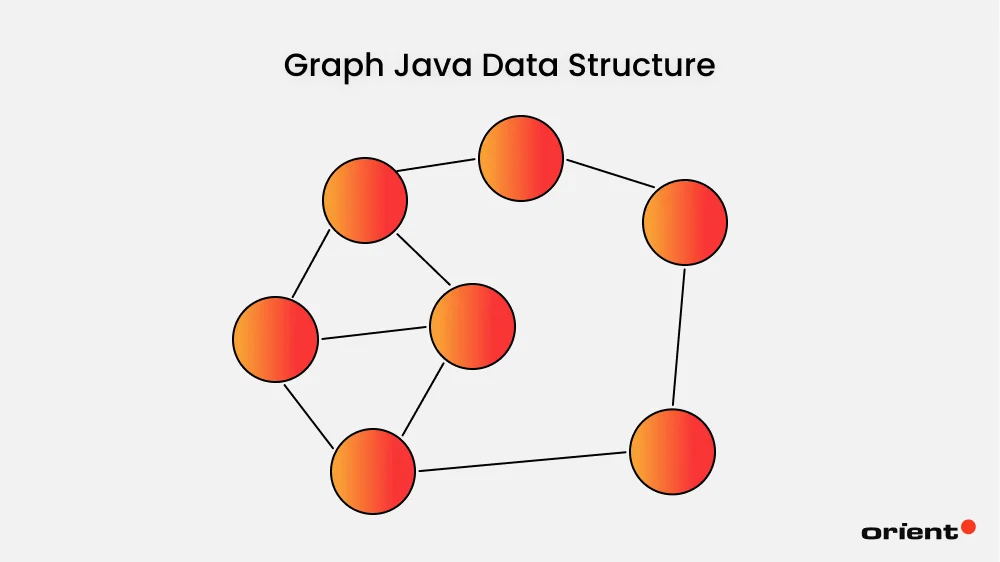
Vertices are sometimes referred to as nodes, and “represented” by dots. Edges are lines that connect those dots (vertices). This widely used data structure is used in social network analysis, network routing, or biological data analysis.
In short, graphs are used to represent relationships between different entities.
Types of Graphs
There are seven main types of graphs every developer needs to know.
- Undirected Graphs: In this type of graph, edges have no direction. Connections go both ways. Think of mutual friendships on social media.
- Directed Graphs (Digraphs): Edges have direction, showing one-way relationships, like links between web pages.
- Weighted Graphs: Each edge has a numeric value (weight) that represents cost, distance, or importance. This is useful in transport or network optimization.
- Unweighted Graphs: Edges only show connections, without any weights, and are often used in basic social or communication networks.
- Cyclic and Acyclic Graphs: Cyclic graphs have loops; acyclic ones don’t. Directed acyclic graphs (DAGs) are often used in project scheduling to avoid circular dependencies.
- Connected and Disconnected Graphs: Connected graphs have a path between every node; disconnected ones have isolated parts.
- Bipartite Graphs: Nodes are divided into two groups, and edges only connect nodes from different groups, which is useful for matching or resource allocation problems.
Graph Representation in Java
In Java, the two most common ways to represent graphs are adjacency matrices and adjacency lists.
Adjacency Matrix
Represents connections using a 2D array where each cell shows whether two nodes are connected.
An adjacency matrix is best for dense graphs (with lots of connections).
int[] [] graph = {
{0, 1, 1},
{1, 0, 0},
{1, 0, 0}
} ;
// Node 1 connects to nodes 2 and 3
Adjacency List
Each node keeps a list of its neighbors. This is more memory-efficient for sparse graphs (with fewer connections).
import java.util.*;
List< List< Integer >> graph = new ArrayList<>();
graph.add(List.of(2, 3)); // Node 1 → 2, 3
graph.add(new ArrayList<>()); // Node 2 → none
graph.add(new ArrayList<>()); // Node 3 → none
Wrapping Up – What Are Data Structures Really About?

Data structures take time and effort to learn and understand thoroughly. However, once you fully grasp these key concepts of Java programming, you’ll recognize and see its magic in almost every aspect of software development. Every data structure’s main goal is storing and finding data, and though different, they all aim to make this task faster and more convenient.
Perhaps you are looking for a team that is well-versed in data structures, not only in Java, but also in other languages. Look no further! Orient Software team holds two decades of experience and is happy to chat and help you bring your IT visions to life. Reach out to us today and discover what we can do for you!







