How Chaos Engineering Can Help Prevent System Failures and Outages

Content Map
More chaptersThe advent of cloud computing and microservices makes applications and websites become more complicated. This complexity has made it easier for failure points and vulnerabilities to appear. As a result, threat actors have more opportunities to breach and compromise a distributed computing system. To test the integrity and resilience of a computing system, a DevOps team may utilize a technique called chaos engineering.
Read on to find out what chaos engineering is, the advantages, the types of chaos engineering, and the best practices to follow.
Key Takeaways:
- Chaos engineering can effectively address issues in a computing system before threat actors strike.
- By using the right tools, technologies, and procedures, DevOps teams can use chaos engineering to strengthen the resilience and security of a computing system.
- Some of the best practices to follow when performing chaos engineering are to understand a system, define clear objectives, and take advantage of automation.
What Is Chaos Engineering?
Chaos engineering is the intentional and controlled disruption of distributed systems. The purpose is to identify and address potential flaws, bugs, errors, and vulnerabilities - before they cause service-disrupting issues. DevOps teams typically perform this activity in a production or pre-production environment. The former is the live environment that real users engage with, while the latter is a test environment that only engineering teams can use.
Chaos engineering allows DevOps teams to understand how a distributed computing system responds to different incidents. After each test, the team will make any necessary adjustments to reduce the potential harm of an incident. They achieve this by using various tools, techniques, and technologies to plan, execute, and analyze all of their chaos engineering activities in a controlled, centralized environment.
What Are the Benefits of Chaos Engineering?
The main advantage of chaos engineering is that it helps DevOps teams identify and address weak points in complex systems early. By doing so, they can assess how a system responds to a problem, and they can either eliminate the source of the problem or minimize the harm and spread.
Other advantages of chaos engineering include being able to:
Maintain Business Continuity

Between 2020 and 2022, 18% of organizations ranked their most impactful outage (either in their facility or due to a third-party service provider) as ‘Significant.’ The same study found the leading cause of significant outages to be network-, power-, IT system-, and third-party IT service-related issues.
With chaos engineering, you can test for issues that – if left unchecked – could disrupt your business, from security gaps and performance bottlenecks to hidden bugs and glitches. Whether this work is behind the scenes or outside peak hours, you can test for these issues and keep your business running.
Improve Cyber Security Resilience

The global cost of cybercrime acts is estimated to reach 23.82 trillion by 2027, according to Statista.
Many high-profile cyberattacks occurred in 2023. In May, hackers breached Microsoft’s cloud-based Exchange email platform, stealing over 60,000 emails from U.S. State Department accounts. Meanwhile, the UK Royal Mail service was the victim of a successful cyberattack, temporarily preventing 11,500 Post Office branches from handling international mail or parcels.
By proactively testing how vulnerable a system is to a security breach, DevOps teams can find and fix any issues before a hacker does. These include security loopholes caused by poor code, misconfigurations, and poor access management.
Improve Scalability

Companies that can upscale comfortably have a better chance of maintaining a competitive edge, meeting dynamic consumer demand, and staying updated on the latest technology.
Unfortunately, upscaling can be risky if companies don’t know if their system can handle incidents. For example, if a system were to experience a sudden spike in network traffic, would it cope under pressure or exhibit signs of poor performance, such as slow-loading pages? Furthermore, if a system running on a microservices architecture were to experience a service failure, would that failure impact just one service or the entire ecosystem?
By defining how a system should behave under normal circumstances (steady-state behavior), DevOps teams can intentionally introduce different incidents to measure their impacts on the system. If performance falls below expectations, they can take the steps necessary to either reduce the effects of such an incident or, if possible, prevent them from occurring in the first place.
Types of Chaos Engineering Techniques and Procedures
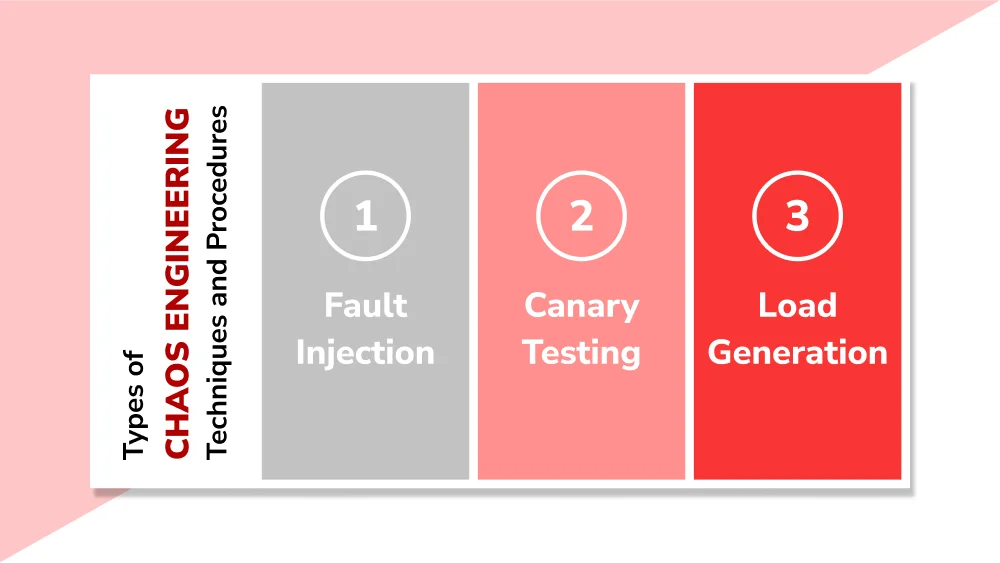
DevOps teams use various tools, techniques, and procedures to conduct chaos engineering experiments. The methods they employ depend on the purpose of the test. For example, if the goal is to evaluate the effects of a slow or failing network connection, the chaos engineering team would use latency injecting to delay the network and slow down response times.
Other types of chaos engineering techniques that DevOps teams use include:
Fault Injection
A fault injection intentionally introduces faults and errors into a distributed computing system. These faults are designed to disrupt the system in different ways, such as terminating processes and inducing disk read errors. This practice helps DevOps teams understand how a system responds to certain incidents, and it can help them identify and address different failure points.
The most popular fault injection tools are the AWS Fault Injection Simulator (FIS) and AWS Resilience Hub, which include various fault templates that users can inject into production environments and pre-production environments.
Canary Testing
Canary testing involves releasing a new feature or product to a small group of users. The primary goal of canary testing is to uncover any bugs, errors, or faults within a new feature or product to a small percentage of the user base. In doing so, chaos engineers can address any issues before the final release.
During canary tasting, the unaffected user base (those who have not received the new feature or product) can continue to access the existing version of the relevant application or website.
Load Generation
Also known as load testing, load generation sends large volumes of traffic to a computing system – typically well beyond normal operations. Lead generation sees how a system responds to either short or prolonged periods of high user activity.
DevOps teams may perform load generation to:
- Establish a baseline user cap: The maximum number of users the system can accept before impacting performance.
- Evaluate the performance of specific hardware components: These include hardware like CPU and GPU load limits. If the hardware struggles to perform mission-critical tasks, a DevOps team may advise a company to invest in new infrastructure.
Load-generation tools allow DevOps teams to manage all of their load-generation activities in one place. They typically have a user interface that teams can use to prepare scripts, deploy scripts, monitor and analyze real-time data, and produce comprehensive reports.
How do load testing and performance testing differ? Load testing evaluates software behavior under high loads, while performance testing evaluates software behavior under normal circumstances.
Best Practices to Follow in Chaos Engineering

Aside from using the right tools and techniques, DevOps teams must ensure that chaos engineering achieves the desired outcomes and keeps business disruption low. Embracing creative problem-solving and using manual and automation testing also yield positive results.
Here are the best practices for a DevOps team to follow in chaos engineering:
Understand the System First
Understand what the system is and how it should behave under normal circumstances. This usually involves evaluating and understanding its functions, architecture, dependencies, and performance metrics like latency and availability.
By doing so, DevOps teams have baseline numbers that they can use to measure the difference between healthy and unstable performance during each test.
Define Clear Objectives
Define the purpose of all chaos experiments and outline the steps required to achieve a particular goal.
For example, let’s say the goal is to measure the effects of a database outage. Then, DevOps teams can choose and configure the necessary tools to temporarily disrupt a database and evaluate its effects on the system.
Embrace Automation
When done correctly, teams can use DevOps automation for various chaos engineering activities. These include tasks like designing and running chaos experiments and producing chaos engineering reports. By doing so, they can save time on manual labor and produce consistently accurate results.
Embracing Chaos Engineering for Better Software
Chaos engineering is an effective way to find and fix weak points in a distributed system. It can also help you determine how well your system will respond to unexpected situations. For example, if you want to know how many users your application can handle at once, chaos engineering can help you set the right capacity limit.
There are also various pre-built chaos engineering tools, such as Chaos Kong, Chaos Monkey, and LitmusChaos. These tools have clean user interfaces, monitoring capabilities, and templates that DevOps teams can use to trigger specific errors on and off.
At Orient Software, chaos engineering is an integral part of our QA and software testing procedures. By using the latest tools, technologies, and procedures, our expert development teams can identify potential flaws in your system and propose remediation strategies to prevent or limit the effects of a negative incident.
For more information about our QA and software testing services, contact us today.

Shannon Jackson-Barnes
Writer
Shannon Jackson-Barnes
Writer